

The agentic AI era has arrived — are we ready?
Something fundamental shifted in the last 18 months. AI stopped being a sophisticated question-answering system and became something that acts. Not just surfacing an insight, but executing on it — running queries, catching failures, iterating on its own output, and delivering a finished result without a human in the loop at every step.
That transition has a name: agentic AI. And understanding it — not just using it as a black box — is becoming one of the most strategically important competencies across data, engineering, and business functions.
From System 1 to System 2: the architectural shift
Researchers frame this transition as moving from System 1 AI to System 2 AI, borrowing from cognitive psychology. System 1 is fast, reactive, and single-shot — you send a prompt, you receive a response, the interaction ends. Virtually every enterprise LLM deployment before 2024 was System 1. Useful, but fundamentally a stateless lookup with language fluency bolted on.
System 2 is categorically different. It is deliberate, multi-step, and self-correcting. An agent operating in System 2 mode maintains a goal across time, selects and invokes tools, evaluates intermediate results, revises its approach when something fails, and terminates only when the objective is genuinely satisfied — or when it determines the objective cannot be met and says so.
The academic literature on this has compounded rapidly. The production deployments are live. And the gap between what agents can now reliably do and what most organisations know how to do with them has never been wider.
That gap is the professional opportunity of this decade.
Why the market is not a projection — it is already moving
Agentic AI is not a future-state technology. It is a present-tense infrastructure shift affecting every industry that runs on knowledge work.
Claims processing in insurance. Clinical documentation in healthcare. Financial reconciliation. Supply chain exception handling. Automated code review. Data quality monitoring at scale. Customer escalation routing. In every one of these domains, the core workflow follows the same pattern: perceive a situation, reason about it, take an action, observe the result, decide what comes next. That is precisely the loop that agents are designed to execute — reliably, at scale, without fatigue.
Analysts projecting the agentic AI market to exceed $100 billion by 2030 are not being speculative. They are counting the workflows. The organisations that build the internal capability to design, deploy, evaluate, and govern these systems will accumulate a structural advantage that compounds over time. The professionals who can bridge business logic and agentic architecture are already scarce. That scarcity is accelerating.
Who needs to understand this, and why
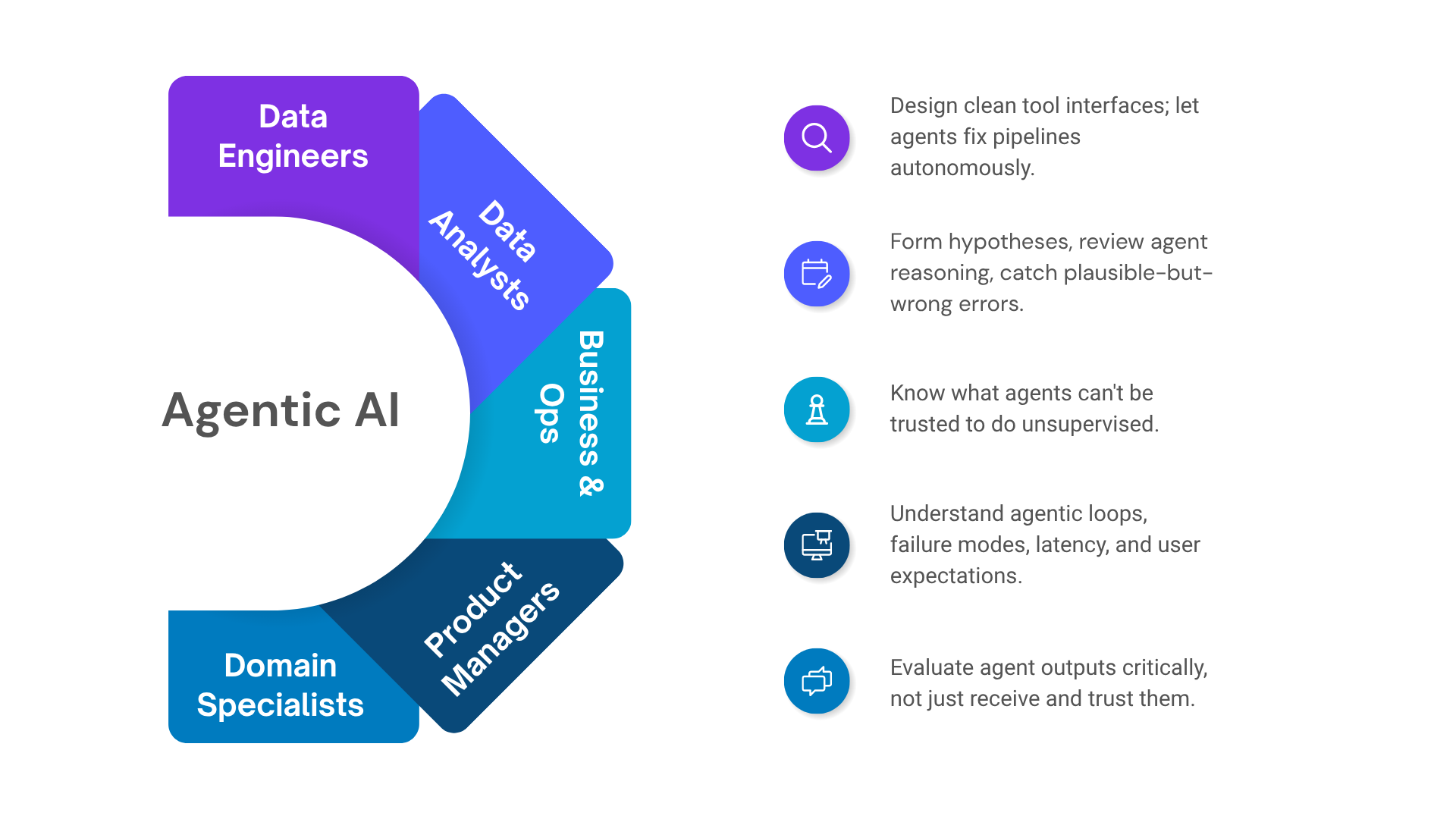
The agentic shift does not belong to engineers alone. It redistributes leverage across every function that touches data, process, or product.
Data engineers are seeing pipelines evolve toward self-healing architectures. An agent with access to an orchestration layer can detect a failing model, trace the upstream lineage, identify schema drift, propose a fix, and open a pull request — autonomously. The engineering skill that matters is no longer writing every conditional branch. It is defining clean tool interfaces, establishing trust boundaries, and designing systems that fail gracefully rather than silently.
Data analysts and scientists are moving from executing analyses to reviewing and directing them. An agent can write the SQL, validate row counts, try an alternate aggregation when the first looks anomalous, and deliver a structured finding. The analyst's leverage shifts toward forming better hypotheses, interrogating agent reasoning, and catching the subtle errors that feel plausible but are wrong. That requires a deeper understanding of how agents reason — not less.
Business and operations professionals are in a more surprising position than they realise. The distance between "I know what this process should do" and "it runs without me" is collapsing. Agents that update CRM records, draft follow-ups, route escalations, and flag exceptions do not require deep technical knowledge to use effectively. They do, however, require people who understand what agents can and cannot be trusted to do — and how to design workflows that remain auditable.
Product managers now need this as a foundational literacy. Scoping a feature that involves an agent means understanding the difference between a single-turn LLM call and an autonomous multi-step loop, the failure modes of each, the latency and cost implications, and the user expectations each pattern creates. This is no longer optional depth.
Domain specialists in finance, healthcare, and supply chain face a near-term reality: the tools in their domain are going agentic, and the professionals who can evaluate those systems critically — rather than simply receiving their outputs — will carry significantly more institutional weight.
What the loop actually looks like in code
The architecture is simpler than it sounds. An agent is, at its core, a while loop wrapped around an LLM call with tools attached.
Here is a production-pattern data analyst agent in Python, using the Anthropic SDK. It accepts a plain-language business question, writes and executes its own SQL, reviews the results, and iterates until it has a complete and coherent answer:
A few things worth noting in this implementation. The agent has two tools, not one — run_sql for data retrieval and write_finding for structured output. This separation matters: it gives the agent a clear signal for when analysis is done rather than just when it has run some queries. The system prompt is explicit about methodology, which dramatically reduces the rate of shallow or hallucinated analyses. And the iteration cap is a production necessity — agents without bounds can loop indefinitely on ambiguous inputs.
This is roughly 80 lines including comments. A production version would add tool-call logging, result caching, error retry logic, and evaluation hooks. But the core architecture is already here.
How to build the skill progressively
The path from awareness to proficiency is well-defined, and shorter than most people assume.
Start with the mental model. Before touching any platform or writing any code, internalise the loop: perceive a goal, reason and plan, invoke a tool, observe the result, decide what comes next. Everything in agentic AI — multi-agent systems, memory architectures, MCP integrations — is a variation on this pattern.
Add tools incrementally. Begin with one tool against a real system. Watch where the agent gets stuck. What happens when the tool returns an unexpected schema? What does it do when a query fails? The failure modes teach you more than the successes.
Learn MCP deliberately. The Model Context Protocol standardises how agents interface with external systems. A tool you define to the MCP spec can be consumed by any compatible agent runtime. This moves you from building one-off experiments to building reusable, composable infrastructure — which is where real leverage lives in production environments.
Then advance to the frontier problems: persistent memory across sessions, multi-agent delegation patterns, evaluation frameworks for measuring reliability, and governance models for high-stakes automated decisions. These are the problems that separate teams building toy demos from teams running agents in production.
The case for acting now
The production tooling has matured significantly faster than the talent pipeline to support it. Most organisations deploying agents today are doing so without people who genuinely understand the loop, the failure modes, or the right architectural patterns. That creates compounding risk — and compounding opportunity for professionals who close the knowledge gap now.
The agentic AI era is not on the horizon. It is already here, already running in production systems that affect real decisions. The question is not whether to engage with it — the question is whether you are equipped to shape it, evaluate it, and take responsibility for what it does.
That is a skill worth building. And the window to build it ahead of the curve is still open, but not indefinitely.
Explore more writing on topics that matter.