

The Complete Stack — Seven Layers
AI healthcare systems are not single models. They are vertically integrated stacks where each layer must be designed for clinical correctness, regulatory compliance, and operational resilience. A production system at a hospital or pharma company spans seven layers: interfaces (EHR APIs, FHIR endpoints), AI services (clinical NLP, imaging AI, LLM agents), MLOps (MLflow, Kubeflow, model monitoring), ML/DL frameworks (PyTorch, MONAI, scikit-learn), the data layer (FHIR R4, HL7, DICOM, OMOP CDM), compliance (HIPAA de-identification, GDPR, FDA SaMD audit logs), and infrastructure (Kubernetes, Airflow, Kafka, GCP/AWS GovCloud).
Key insight: Most ML practitioners underestimate the interface, data standard, and compliance layers. These are where clinical AI projects most commonly fail or get blocked by procurement and legal — not in model accuracy.
Data Layer — FHIR, HL7 & DICOM
Healthcare data is radically different from general-purpose data. It arrives in clinical standards (FHIR, HL7, DICOM), spans structured codes (ICD-10, SNOMED CT, LOINC, RxNorm), and must be treated as patient-linked sensitive data from the moment it is ingested.
FHIR R4 — Fast Healthcare Interoperability Resources
FHIR is the dominant modern standard for exchanging clinical data via REST APIs. Understanding resources, bundles, and SMART on FHIR auth is non-negotiable for any AI healthcare engineer.
DICOM — Medical Imaging Standard
DICOM is the universal format for medical imaging — CT, MRI, PET, X-ray, ultrasound. Every pixel of every clinical scan arrives wrapped in DICOM metadata. You cannot build medical imaging AI without mastering it.
Controversy — FHIR Is Not as Interoperable as Advertised: While FHIR R4 is mandated under the 21st Century Cures Act, every major EHR vendor implements it differently. Epic's FHIR sandbox exposes a curated subset of resources; structured data critical for AI — detailed procedure notes, nuanced medication dosing, device data — is often inaccessible or buried in unstructured text. Real AI pipelines still rely heavily on proprietary Epic/Cerner APIs, bulk FHIR exports requiring separate vendor agreements, or direct database access.
OMOP Common Data Model — Research-Grade Standardization
For research and ML training across multiple hospital systems, OMOP CDM is the gold standard. It maps ICD, SNOMED, RxNorm, and LOINC to unified concept IDs, enabling multi-site studies without data sharing.
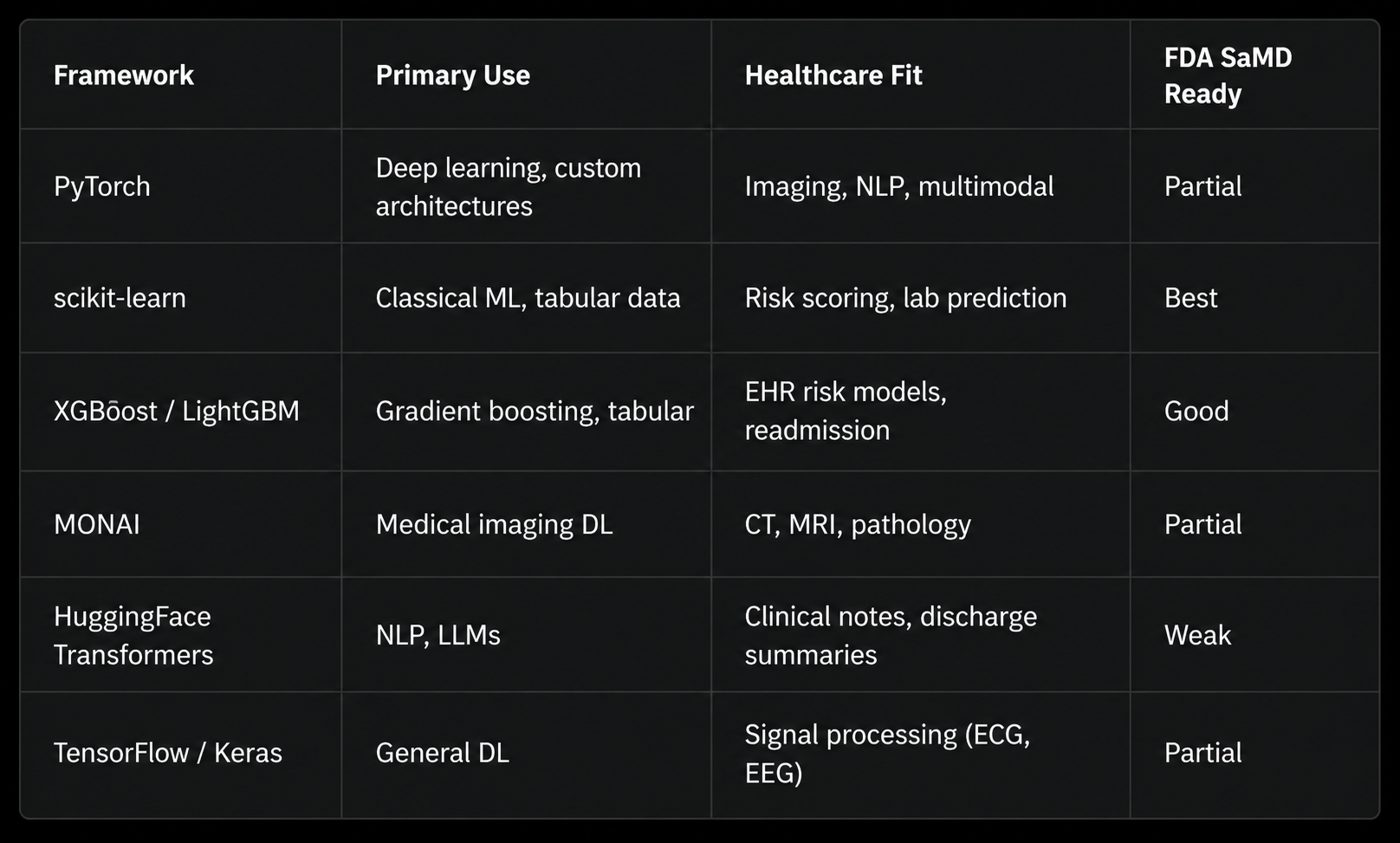
ML / Deep Learning Frameworks
The ML layer sits atop the data layer and below the clinical interface. Choosing the right framework is a function of task type, data modality, and regulatory classification of the model output.
Risk Scoring with XGBoost + SHAP
The most commonly deployed AI model in hospitals is not a transformer — it is a gradient-boosted tree predicting readmission risk, sepsis onset, or deterioration from structured EHR features.
Clinical NLP & Large Language Models
Around 70–80% of actionable clinical information exists in unstructured text: physician notes, discharge summaries, radiology reports, pathology reports, operative notes. Clinical NLP extracts structured knowledge from this text. Modern LLMs are rapidly reshaping this space — not without significant controversy.
Named Entity Recognition with ClinicalBERT
LLMs in Clinical Settings — Structured Extraction
Foundation LLMs are being tested for discharge summary generation, clinical decision support, and patient-facing Q&A. The engineering challenge is not just accuracy — it is structured output, hallucination control, and latency within clinical workflow.
Controversy — LLM Hallucination in Clinical Contexts Is a Patient Safety Issue: LLMs hallucinate drug interactions, fabricate dosing information, confabulate lab reference ranges, and express false confidence on rare-disease presentations — precisely the cases where clinical judgment matters most. The NEJM AI editorial board has called for a moratorium on LLM clinical decision support deployment without prospective randomized controlled trials. As of 2025, no LLM has FDA clearance as a clinical decision support system.
Medical Imaging AI with MONAI
Medical imaging is the single most commercially successful AI vertical in healthcare. The FDA has cleared over 950 AI/ML-based medical devices as of 2025, the majority in radiology. The dominant framework is MONAI (Medical Open Network for AI), a PyTorch-based framework built by NVIDIA and the clinical AI community.
Controversy — The "AI Radiologist" Headline vs. Clinical Reality: A 2021 systematic review (Nagendran et al., BMJ) examined 81 head-to-head AI-vs.-clinician studies and found 70 had high risk of bias, none were prospective randomized trials, and almost all tested AI on data from the same institution used for training. When models are tested at different hospitals or on different scanner models, performance drops are frequently large and clinically significant — a phenomenon called dataset shift.
Federated Learning — Training Without Moving Data
Federated learning (FL) solves one of healthcare AI's hardest problems: how to train on data from multiple hospitals without ever sharing patient records. Each hospital trains a local model on its own data and shares only model weights (gradients), aggregated at a central server.
Open Question — Does Federated Learning Actually Preserve Privacy? Gradient inversion attacks (Zhu et al., NeurIPS 2019; Geiping et al., NeurIPS 2021) have demonstrated that training images — including medical images — can be partially or fully reconstructed from gradients, particularly in early training rounds with small batch sizes. Combining FL with differential privacy adds formal guarantees but at significant accuracy cost. The field has not yet found a principled resolution to this tension.
MLOps for Healthcare — Production Is Different Here
Healthcare MLOps has requirements that don't exist in standard ML engineering: model versioning tied to regulatory submissions, mandatory audit trails, clinical performance drift monitoring, and the ability to roll back a deployed model within hours if a safety signal emerges.
Regulatory Requirement: Under FDA's proposed AI/ML SaMD framework and the EU AI Act, any model update — including retraining on new data — may constitute a "significant change" requiring re-submission or 510(k) notification. Change-management controls must be integrated from day one, not retrofitted after deployment.
HIPAA, GDPR & Regulatory Compliance
Compliance is not a legal checkbox — it is an engineering discipline. HIPAA's Safe Harbor de-identification standard specifies 18 PHI identifiers that must be removed or transformed. Non-compliance exposes institutions to penalties of up to $1.9M per violation category per year (HIPAA) and 4% of global annual turnover (GDPR).
Explainability, Trust & Clinical Governance
A model that cannot explain its predictions to a clinician cannot safely be used in clinical decision-making. Explainability in healthcare is a precondition for physician trust, institutional liability management, and in the EU, a legal right under GDPR Article 22.
Controversy — SHAP and Grad-CAM Don't Actually Explain Models: Research by Rudin (2019, Nature Machine Intelligence) argues post-hoc explanations of black-box models are inherently unreliable: SHAP values change under perturbations that don't change model predictions. Adebayo et al. showed Grad-CAM saliency maps from a fully randomized neural network are visually indistinguishable from those of a trained model. The counterclaim: a Grad-CAM overlay showing the model focused on a lesion rather than an image artifact is actionable, even without mechanistic interpretation.
Controversies — What the Field Gets Wrong
The Racial Bias Problem Is Structural, Not Fixable by Debiasing
A 2019 Science paper (Obermeyer et al.) revealed a widely-used commercial healthcare algorithm systematically under-referred Black patients for high-risk care by using healthcare costs as a proxy for healthcare needs — a structurally racist proxy, since Black patients receive less care for equivalent illness severity due to systemic factors. Post-hoc debiasing can reduce bias on measured metrics while amplifying it on unmeasured ones. Critics argue that fair clinical AI requires first fair clinical systems — no debiasing technique can make an unjust dataset just.
The Academic-to-Deployment Gap Is Wider Than Reported
A 2021 Lancet Digital Health analysis reviewed 415 clinical AI papers in high-impact journals and found fewer than 2% were prospective clinical trials. The rest were retrospective analyses on curated, single-institution datasets. Several high-profile tools failed in prospective deployment — most notably the Epic sepsis model, which had a published AUROC of 0.76 but was independently evaluated at AUROC 0.63 in production, with high false positive rates leading to alert fatigue.
Data Governance in AI Training Is a Legal Minefield
Multiple major AI healthcare companies have faced legal challenges over patient data use. Google's Project Nightingale accessed medical records of approximately 50 million Americans without individual patient consent — permissible under a HIPAA Business Associate Agreement but widely criticized. The core legal tension: HIPAA permits use of de-identified data and BAA-covered PHI for treatment, payment, and healthcare operations — but training a commercial AI model arguably falls outside those categories. No court has definitively ruled on this.
Open Questions — The Research Frontier
These are the questions leading researchers are actively working on and haven't solved. Mastering AI healthcare means knowing where the field's knowledge ends.
Causality vs. correlation in EHR models. When a readmission model learns that patients discharged on Fridays are more likely to be readmitted, is it learning a causal signal or a confound of social determinants of health? How do we train models that learn causal mechanisms rather than hospital workflow artifacts?
Foundation models for medicine — are they ready? Models like Med-PaLM 2 and GPT-4 score highly on medical licensing exams. But USMLE-level reasoning is not the same as clinical decision-making. How do we evaluate clinical reasoning, not clinical recall?
Uncertainty quantification for high-stakes decisions. When a model is 65% confident in a diagnosis, what does that mean clinically? Bayesian deep learning, conformal prediction, and ensemble methods all produce confidence estimates — but calibration to real-world clinical outcomes at the patient level remains unsolved.
Continuous learning without catastrophic forgetting. Clinical distributions change: new pathogens, updated treatment guidelines, demographic shifts. How do you continuously update a deployed clinical AI model without degrading performance on the cohorts it was originally validated on?
The rare disease problem. Most EHR training datasets have fewer than 100 cases of most rare diseases. Standard deep learning fails at this sample size. Few-shot clinical reasoning — learning from 5–20 examples — remains an open research problem with enormous clinical value.
Multimodal clinical AI at scale. A physician integrates imaging, labs, vital signs, notes, and patient history simultaneously. Building AI systems that do the same — without privileging one modality or requiring all modalities at inference — is the grand challenge of clinical AI architecture.
The deepest open question — does clinical AI actually improve outcomes? As of 2025, fewer than 30 randomized controlled trials have tested whether AI clinical decision support actually improves patient outcomes. Several of the best-powered trials have been neutral or negative: a 2023 NEJM trial of AI-assisted diabetic retinopathy screening showed no improvement over standard care; a 2022 JAMA trial of AI sepsis alerts found increased alert fatigue with no mortality benefit. The field is, in the most charitable reading, ten years away from having the clinical trial data needed to answer this question rigorously. Practitioners who understand this uncertainty — and build AI systems that generate the evidence for their own validation — will define the next generation of the discipline.
Further Reading: Obermeyer et al., Science 2019 · Nagendran et al., BMJ 2020 · Rudin, Nature Machine Intelligence 2019 · Adebayo et al., NeurIPS 2018 · Wong et al., JAMA Internal Medicine 2021
Explore more writing on topics that matter.